Solution: DFS with memorization
This is a similar problem to Regular Expression Matching. However, the test data on leetcode OJ here is much stronger. The length of string can be over 1000. For problem, Regular Expression Matching, I wrote a DFS with memorization solution, which solved the problem in 50ms. However that solution will explode the memory in this problem.
To solve this problem, I added more pruning into the search and finally avoided MLE and solved it on OJ in 528 ms (Not good!).
Anyway, here comes the code and the two prunings I used are explained in the comments.
The time complexity complexity is , as we use visited to record if a position pair is visited. The space complexity is also
Code
1 class Solution {
2 public:
3 bool isMatch(const char *s, const char *t) {
4
5 // simplify pattern "a***b" into "a*b"
6 int on_streak = 0;
7 char tProxy[strlen(t)];
8 int tLen = 0;
9 for (int i = 0; t[i]; ++ i){
10 if (on_streak && t[i] == '*')
11 continue;
12 on_streak = (t[i] == '*')?1:0;
13 tProxy[tLen++] = t[i];
14 }
15 tProxy[tLen] = 0;
16
17 // record which pair of positions are visited, details go in dfs function
18 unordered_set<int>visited;
19
20 // realNum[i]: number of non-"*" chars in tProxy[i..tLen], for pruning
21 int realNum[tLen+1];
22 realNum[tLen] = 0;
23 for (int i = tLen-1; i >= 0; -- i)
24 realNum[i] = (tProxy[i] == '*')?realNum[i+1]:realNum[i+1] + 1;
25
26 bool re = dfs(0, 0, s, strlen(s), tProxy, tLen, visited, realNum);
27
28 return re;
29 }
30
31 bool dfs(int idx1, int idx2, const char s[], int sLen, char t[], int tLen, unordered_set<int >&visited, int num[]){
32 // case1: both reach ends, case2: s reach ends, t only has '*' remained
33 if ((!s[idx1] && !t[idx2]) || (!s[idx1] && !num[idx2]) )
34 return true;
35
36 // PRUNING: ignore the visited pair of positions
37 if (visited.count(idx1*(tLen+1) + idx2))
38 return false;
39
40 visited.insert(idx1*(tLen+1) + idx2);
41
42 if ( (!s[idx1] && t[idx2]) || (s[idx1] && !t[idx2]) )
43 return false;
44 //match
45 if (s[idx1] == t[idx2] || t[idx2] == '?' || t[idx2] == '*'){
46 if (dfs(idx1+1, idx2+1, s, sLen, t, tLen, visited, num))
47 return true;
48 }
49 // other two cases for '*'
50 if (t[idx2] == '*'){
51 // PRUNING: numer of remaining chars in s should be greater or equal to non-"*" in t
52 // otherwise, impossible to match
53 // e.g. s = "aaab" t = "??bbb*"
54 if (sLen - idx1 - 1 >= num[idx2] && dfs(idx1+1, idx2, s, sLen, t, tLen, visited, num))
55 return true;
56 if ( sLen - idx1 >= num[idx2+1] && dfs(idx1, idx2+1, s, sLen, t, tLen, visited, num))
57 return true;
58 }
59
60 return false;
61 }
62 };A DP solution
Let us define match[i][j] to indicate if string s[0...i-1] can match pattern t[0...j-1] or not. Then the state transition function is
- if
t[j-1] == '*',match[i][j] =match[i-k][j-1]
- if
t[j-1] != '*',match[i][j] = (match[i-1][j-1]) && (s[i-1] == t[j-1] || t[j-1] == '?')
As match[*][j] only relies on match[*][j-1], we can use 1-D array instead of 2-D array.
Code
Unfortunately this code will lead to TLE. There is some SPECIAL test case that requires that you treat it special (if you paste this code into OJ, you will see that case). I really dislike this kind of requirement, as we already reached a solution with the best time complexity and neat code implementation.
1 class Solution{
2 public:
3 bool isMatch(const char *s, const char *t) {
4 int sLen = strlen(s), tLen = strlen(t);
5 bool match[sLen+1];
6 memset(match, 0, sizeof(bool) * (sLen + 1));
7 match[0] = true;
8 int firstTruePos = 0;
9 for (int j = 1 ; j <= tLen; ++ j){
10 if (t[j-1] != '*'){
11 firstTruePos = sLen+1;
12 for (int i = 1; i <= sLen; ++ i){
13 match[i] = (match[i-1]) && (s[i-1] == t[j-1] || t[j-1] == '?');
14 if (firstTruePos == sLen+1 && match[i]) firstTruePos = i;
15 }
16 }
17 else{
18 for (int i = 1; i <= sLen; ++ i)
19 match[i] = (i < firstTruePos)? false: true;
20 }
21 match[0] = match[0] && (t[j-1] == '*');
22 if (match[0]) firstTruePos = 0;
23 }
24 return match[sLen];
25 }
26 };A Greedy Solution
The key thoughts of this greedy solution are
- we only care about the last asterik we met.
- Every time a mismatch happens, one character in
swill be absorbed by the the nearest asterik.
The conditions for failure of match is
- if no asterik has been spotted before a mismatch happens
- if we find there is no chars left in
s, while we still have patterns (chars except asterisk) left inp
The description above is too abstract, let me use a GIF to illustrate how this greedy algorithm works.
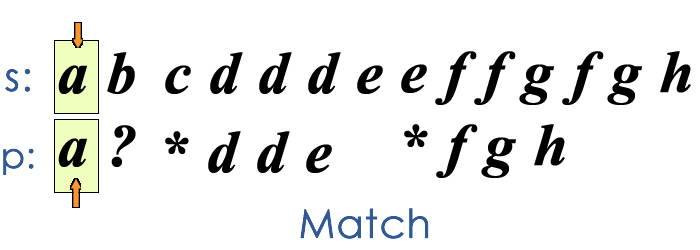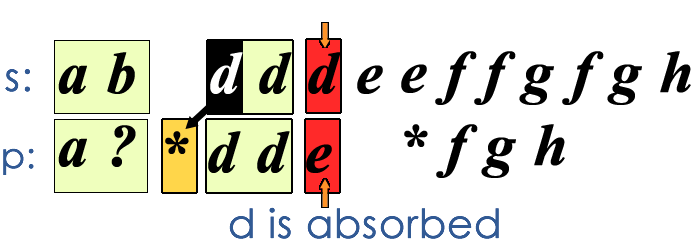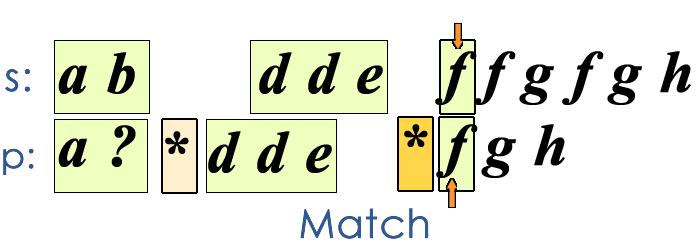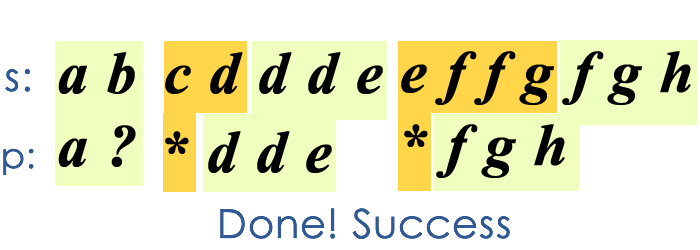
The time complexity of this algorithm is still , but as it is pretty “aggressive”, it only need linear time for some special cases and the average performance is better than the DP solution.
Code
Here is my implementation.
1 class Solution {
2 public:
3 bool isMatch(const char *s, const char *t){
4 int i = 0, j = 0;
5 int lastAsterPos = -1;
6 int toAbsorb = -1;
7 while(s[i]){
8 if (t[j] == '*'){ // Asterisk
9 lastAsterPos = j ++;
10 toAbsorb = i;
11 }
12 else if (s[i] == t[j] || t[j] == '?') //match
13 i++, j ++;
14 else{ //mismatch
15 if (lastAsterPos == -1) return false;
16 j = lastAsterPos + 1;
17 i = ++toAbsorb;
18 }
19 }
20 while(t[j] == '*')
21 j++;
22 return (!t[j]);
23 }
24 };